
Voltar ao hub
Blog
IA
Qwen 3.5 9B Review: Alibaba's Open Source Model Tested
Publicado em 9 de mar. de 2026Atualizado em 27 de mai. de 2026
At Emelia.io, we rely on AI to power our B2B prospecting platform, from automated cold email campaigns to data enrichment. API costs for AI models represent a significant portion of our operating expenses. That is why Alibaba's release of Qwen 3.5, a family of compact models that can run locally on standard hardware, is a game-changer for us. At Bridgers Agency, our digital agency specializing in AI solutions, we continuously evaluate the best open source models for our clients. Here is our in-depth review.
What Is Qwen 3.5?
On March 1, 2026, Alibaba released Qwen 3.5, a new generation of open source AI models that represents a major milestone for compact LLMs. The family includes four small models: Qwen3.5-0.8B, Qwen3.5-2B, Qwen3.5-4B, and Qwen3.5-9B. These complement the larger models already released, including the flagship Qwen3.5-397B-A17B.
What sets Qwen 3.5 apart is its innovative hybrid architecture. It combines Gated Delta Networks (linear attention) with a sparse Mixture-of-Experts (MoE) system. In practice, the model only activates the network components needed for each task, reducing memory consumption and accelerating inference.
All Qwen 3.5 models are natively multimodal: they process text, images, and video through early fusion of multimodal tokens. They support 201 languages and dialects, up from 119 in the previous generation. The native context window reaches 262,144 tokens, extensible up to 1 million tokens.
Qwen 3.5 9B Benchmarks and Performance
The Qwen3.5-9B is the flagship of the compact series, and its benchmark results are nothing short of remarkable for a model this size.
Benchmark Comparison: Qwen 3.5 9B vs GPT-OSS-120B
Benchmark | Qwen3.5-9B | GPT-OSS-120B | Qwen3-30B-A3B | Qwen3.5-4B |
|---|---|---|---|---|
MMLU-Pro | 82.5 | 80.8 | 80.9 | 79.1 |
GPQA Diamond | 81.7 | 80.1 | 73.4 | 76.2 |
MMLU-Redux | 91.1 | 91.0 | 91.4 | 88.8 |
C-Eval | 88.2 | 76.2 | 87.4 | 85.1 |
IFEval | 91.5 | 88.9 | 88.9 | 89.8 |
MMMLU | 81.2 | 78.2 | - | - |
LongBench v2 | 55.2 | - | - | - |
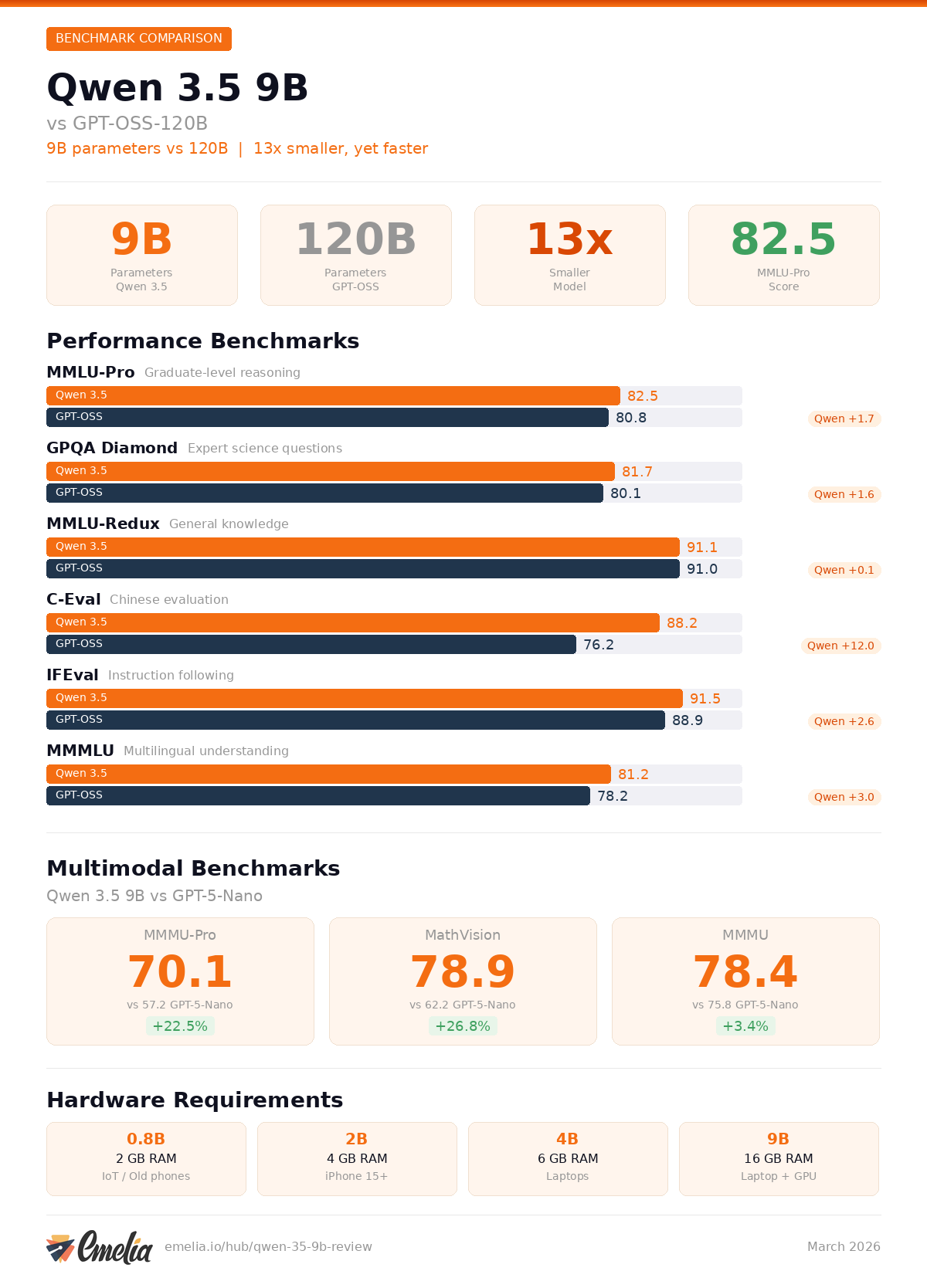
The Qwen3.5-9B outperforms OpenAI's GPT-OSS-120B on MMLU-Pro (82.5 vs 80.8), GPQA Diamond (81.7 vs 80.1), and the multilingual MMMLU benchmark (81.2 vs 78.2). This is especially striking because GPT-OSS-120B is 13 times larger at 120 billion parameters.
Vision and Multimodal Benchmarks
The multimodal dimension is one of Qwen 3.5's strongest advantages. The 9B model excels at visual understanding:
Benchmark | Qwen3.5-9B | GPT-5-Nano | Gemini 2.5 Flash-Lite | Qwen3-VL-30B-A3B |
|---|---|---|---|---|
MMMU-Pro | 70.1 | 57.2 | 59.7 | 63.0 |
MMMU | 78.4 | 75.8 | 73.4 | 76.0 |
MathVision | 78.9 | 62.2 | 52.1 | 65.7 |
Video-MME (with subtitles) | 84.5 | - | 74.6 | - |
OmniDocBench v1.5 | 87.7 | - | - | - |
On the MMMU-Pro visual reasoning benchmark, the Qwen3.5-9B scores 70.1, which is 22.5% higher than OpenAI's GPT-5-Nano (57.2). This is a massive gap that confirms Alibaba's lead in compact multimodal models.
Paul Couvert, founder of Blueshell AI, summarized it on social media: "How is this even possible?! Qwen has released 4 new models and the 4B version is almost as capable as the previous 80B-A3B one. And the 9B is as good as GPT-OSS-120B while being 13x smaller!"
Qwen 3.5 vs GPT: Detailed Comparison
The comparison between Qwen 3.5 and OpenAI's models deserves nuance. While the Qwen3.5-9B surpasses GPT-OSS-120B on several academic benchmarks, OpenAI's model remains stronger on certain complex reasoning and code generation tasks.
For professional use cases, a study by ChartGen AI on 20 data visualization tasks showed GPT-5.2 scoring 178/200 versus 163/200 for Qwen 3.5, but at 10 times the cost. The value proposition clearly tilts in Qwen 3.5's favor.
In practice, Qwen 3.5 excels at:
Multi-step reasoning and agentic tasks
Multimodal understanding (images, video, documents)
Multilingual processing (201 languages)
Instruction following (IFEval: 91.5)
GPT-OSS-120B maintains its edge for:
Complex code generation
Actionable insight extraction from data
Dense reasoning over very long contexts
The real advantage of Qwen 3.5 is its ability to run locally, with zero API calls and zero recurring costs.
Which Qwen 3.5 Model Should You Choose? (0.8B, 2B, 4B, 9B)
Each variant in the Qwen 3.5 small series targets a specific use case. Here is a guide to help you decide:
Model | Parameters | RAM Required | Target Device | Best Use Case |
|---|---|---|---|---|
Qwen 3.5 0.8B | 800 million | 2 GB | Older smartphones, IoT devices | Text classification, simple tasks |
Qwen 3.5 2B | 2 billion | 4 GB | iPhone 15+, mid-range Android | Chatbots, text and image processing |
Qwen 3.5 4B | 4 billion | 6 GB | Recent laptops, flagship phones | Code generation, document analysis |
Qwen 3.5 9B | 9 billion | 10-16 GB | Laptops with 16 GB RAM, dedicated GPU | Advanced reasoning, full multimodal |
The Qwen3.5-4B deserves special mention: it delivers performance close to the previous Qwen3-80B-A3B, a model 20 times larger. For most everyday tasks, it is an excellent balance between performance and resource consumption.
The Qwen3.5-2B is the ideal choice for smartphone deployment. Testers have confirmed it runs on iPhone 17 via MLX with near-instant responses, including image processing.
Qwen 3.5 Hardware Requirements
One of Qwen 3.5's biggest advantages is compatibility with consumer hardware. Here are the requirements by model:
For the Qwen3.5-9B in Q4 quantization (the most common format for local use), you need approximately 10 to 16 GB of total memory (RAM + VRAM). A laptop with 16 GB of RAM is sufficient, with no dedicated GPU required. One developer reported achieving around 30 tokens per second on an AMD Ryzen AI Max+395 processor with Q4_K_XL quantization and the full 256k context window, all with less than 16 GB of VRAM.
For the lighter models:
0.8B: 2-3 GB of memory, runs on virtually any device
2B: 4-5 GB, compatible with iPhone 15 Pro and later in 4-bit mode
4B: 6-7 GB, ideal for entry-level laptops
The model also runs in a web browser, as demonstrated by Xenova, a Hugging Face developer, who ran the model directly in the browser for video analysis.
How to Run Qwen 3.5 Locally on Your Laptop
Installing Qwen 3.5 locally is accessible even for beginners, thanks to tools like llama.cpp. Here is how to get started:
Method 1: Using llama.cpp (Recommended)
llama.cpp is currently the most reliable method for running Qwen 3.5 locally, particularly because Ollama support is still being adapted for the multimodal vision files.
Install llama.cpp from GitHub
Download the quantized GGUF model from Hugging Face:
huggingface-cli download unsloth/Qwen3.5-9B-GGUF --include "*Q4_K_M.gguf"
Launch the model:
./llama-cli -m Qwen3.5-9B-UD-Q4_K_XL.gguf -ngl 99 --temp 0.7 --top-p 0.8 --top-k 20 --min-p 0 --presence-penalty 1.5 -c 16384 --chat-template qwen3_5
Method 2: Using Ollama (Text Only)
If you only need the text capabilities, Ollama remains the simplest option:
Install Ollama from ollama.com
Run the command:
ollama pull qwen3.5
The download is approximately 6.6 GB
Start chatting:
ollama run qwen3.5
Method 3: Using LM Studio
LM Studio provides a user-friendly graphical interface:
Download LM Studio
Search for "unsloth/qwen3.5" in the model library
Select your preferred quantization and download
Enable "Thinking" mode if needed
To toggle reasoning ("thinking") mode on or off, add the parameter --chat-template-kwargs '{"enable_thinking":true}' with llama.cpp. By default, thinking mode is disabled on the small models (0.8B through 9B).
Best Open Source LLM in 2026: Where Does Qwen 3.5 Stand?
The open source model landscape in 2026 is fiercely competitive. Here is how Qwen 3.5 compares to the competition:
Model | Parameters | Type | Key Strength |
|---|---|---|---|
Qwen 3.5 9B | 9B | Hybrid Dense + MoE | Best performance-to-size ratio |
GPT-OSS-120B | 120B | MoE | OpenAI's open source model, very capable |
DeepSeek-V3.2 | - | Dense | Reasoning and agentic workloads |
Llama 4 | Various | Dense | Meta ecosystem, large community |
Mistral | Various | MoE | European models, strong general performance |
The Qwen3.5-9B stands out for its unmatched size-to-performance ratio. No other model under 10 billion parameters delivers comparable results across academic benchmarks, multimodal tasks, and multilingual capabilities.
For businesses and developers looking to deploy AI locally without heavy hardware investment, Qwen 3.5 is arguably the best option available today. The ability to run a model that rivals GPT-OSS-120B on a 16 GB RAM laptop fundamentally changes the economics of AI.
Running Qwen 3.5 on a Smartphone: Edge AI Becomes Real
Perhaps the most exciting aspect of the Qwen 3.5 release is what the smallest models mean for mobile and edge AI. The Qwen3.5-0.8B and Qwen3.5-2B variants are explicitly designed for deployment on phones, tablets, and IoT devices where memory and battery life are critical constraints.
Community testing has confirmed that the 2B model runs smoothly on iPhone 17 Pro using MLX optimization for Apple Silicon. The setup process takes 15 to 20 minutes the first time, and responses are nearly instantaneous after the initial model load. The model processes both text and images offline, with no server connection needed.
For Android devices, the GGUF quantized format allows the 2B model to run on mid-range phones with 6 GB or more of RAM. The 0.8B variant pushes the boundary even further, fitting on older devices with just 2 to 3 GB of available memory.
This is not a toy demo. These models handle real tasks: text summarization, image description, document classification, chatbot interactions, and basic code generation. The 4B variant, which runs on recent laptops and high-end phones, delivers performance that was only achievable with models 20 times its size just months ago.
For businesses building mobile apps that need on-device intelligence, whether for privacy reasons, latency requirements, or cost optimization, this is a pivotal moment.
What Qwen 3.5 Means for the Future of Local AI
The release of Qwen 3.5 confirms a fundamental trend: compact models are catching up to, and sometimes surpassing, giant models on targeted tasks. With a 9-billion-parameter model that can compete with one 13 times its size, Alibaba proves that the race for scale is no longer the only path to performance.
The architectural innovations behind Qwen 3.5, particularly the Gated Delta Networks and sparse MoE approach, point to a future where efficient inference matters more than raw parameter count. The model achieves what Alibaba calls "near-100% multimodal training efficiency compared to text-only training," meaning the vision capabilities come at virtually no performance cost to the language model.
For B2B tools like Emelia.io, this means the possibility of integrating advanced AI features without relying on expensive API calls. For agencies like Bridgers that build custom AI solutions, it opens a new field of possibilities with on-premise, offline, and cost-effective deployments.
As Alibaba's CEO recently confirmed, Qwen will remain open source. This is excellent news for the ecosystem. In a market where the proprietary model arms race keeps driving costs up, having open source alternatives of this caliber accelerates innovation across the entire industry. The question is no longer whether open source models can match proprietary ones, but how quickly the gap continues to close.

Preços claros, transparentes e sem custos ocultos.
Sem compromisso, preços para ajudá-lo a aumentar sua prospecção.
Créditos(opcional)
Você não precisa de créditos se você quiser apenas enviar e-mails ou fazer ações no LinkedIn
Podem ser usados para:
Encontrar E-mails
Ação de IA
Encontrar Números
Verificar E-mails
€19por mês
1,000
5,000
10,000
50,000
100,000
1,000 E-mails encontrados
1,000 Ações de IA
20 Números
4,000 Verificações
€19por mês
Descubra outros artigos que podem lhe interessar!
Ver todos os artigosBlog
Publicado em 5 de abr. de 2025
FullEnrich: opiniões, preços e alternativas para evitar surpresas desagradáveis
 Mathieu Co-founder
Mathieu Co-founderLeia mais
Software
Publicado em 31 de mar. de 2025
9 alternativas ao UpLead para impulsionar REALMENTE sua prospecção
 Niels Co-founder
Niels Co-founderLeia mais
Marketing
Publicado em 2 de mar. de 2025
Plano de ação comercial 2026: método + exemplo outbound
Niels Co-founderLeia mais
Marketing
Publicado em 9 de jun. de 2023
Cold email: guia completo para iniciar em 2026
Niels Co-founderLeia mais
Software
Publicado em 8 de mar. de 2025
7 alternativas a Kaspr para impulsionar sua prospecção B2B
Niels Co-founderLeia mais
IA
Publicado em 18 de jun. de 2025
Os 5 melhores geradores de voz com IA para 2026
Mathieu Co-founderLeia mais
Links úteis
HubCold-email: Guia CompletoEntregabilidade: Guia completoAlternativa ao LemlistAPISolicitar uma demonstraçãoPrograma de afiliadosFind emailSobre
Feedback & RoadmapPolítica de privacidadeCGVAvisos legaisTestimonialsRoadmapAlternativesComparaçõesContactMade with ❤ for Growth Marketers by Growth Marketers
Copyright © 2026 Emelia All Rights Reserved