
GLM-5.1 Review: The Open Source LLM That Codes Autonomously for 8 Hours Straight
Veröffentlicht am 11. Apr. 2026Aktualisiert am 13. Apr. 2026
Z.ai (formerly Zhipu AI) just released GLM-5.1, a 754 billion parameter language model under the MIT license, with a promise that sets it apart from every competitor: it can work autonomously on a single task for 8 hours. Not 8 minutes. Not 8 conversations. Eight hours of planning, execution, iterative optimization, and delivery, across hundreds of rounds and thousands of tool calls.
This is a paradigm shift. Most current LLMs, even the best ones, are evaluated on short tasks: solve a problem, generate a file, answer a question. GLM-5.1 is designed for a radically different use case. It is built as a software engineering agent that stays focused and improves over time, rather than plateauing after a few iterations.
Z.ai is a Beijing-based company spun out of Tsinghua University research. Its founders, professors Tang Jie and Li Juanzi, are recognized figures in Chinese AI research. The company is led by CEO Zhang Peng. With GLM-5.1, Z.ai enters the open model race with an aggressive positioning: MIT license (more permissive than Apache 2.0), open weights on Hugging Face and ModelScope, and compatibility with popular tools like Claude Code and OpenClaw.
The press coverage has been significant, with headlines like VentureBeat's "AI joins the 8-hour work day" capturing the imagination. But beyond the marketing, the technical claims deserve scrutiny. Is this truly a step-change in agent capability, or an incremental improvement wrapped in bold messaging?
How Does GLM-5.1's 8-Hour Autonomous Execution Actually Work?
GLM-5.1's central concept is what Z.ai calls "agentic engineering." Instead of treating each query as an isolated interaction, the model maintains a continuous cycle: experiment, analyze, optimize, repeat. It can iterate over hundreds of rounds with thousands of tool calls before delivering a final result.
The official documentation describes the workflow in four phases: planning, execution, iterative optimization, and delivery. The model does not just generate code and stop. It runs its own tests, analyzes results, identifies weaknesses, and launches another optimization cycle.
To illustrate this concept, Z.ai provides a concrete example on VectorDBBench (a vector database benchmark). On the SIFT-1M dataset with recall at or above 95%, GLM-5.1 achieved 21,500 QPS (queries per second) after more than 600 iterations and 6,000 tool calls. For comparison, the best prior 50-turn result was achieved by Claude Opus 4.6 at 3,547 QPS.
Another example: on KernelBench Level 3 (50 kernel optimization problems), GLM-5.1 achieves a geometric mean speedup of 3.6x over the PyTorch eager baseline. By comparison, standard torch.compile manages 1.15x and max-autotune 1.49x. Claude Opus 4.6 reaches 4.2x, but on a limited number of iterations.
What distinguishes GLM-5.1 is not that it is always the best on any single benchmark, but that it keeps improving where others plateau. The performance curve does not flatten after a few turns.
Technical Architecture: 754B Parameters, MoE, and 200K Context
GLM-5.1 is a massive 754 billion parameter model. It uses a Mixture-of-Experts (MoE) architecture with a specific design described as "glm_moe_dsa," integrating Multi-Latent Attention (MLA, DeepSeek-style) and Dynamic Sparse Attention.
The MoE configuration includes 256 routed experts with 8 active per token, enabling efficient computation despite the total model size. Context is set at 200K tokens with output capacity up to 128K tokens, which is considerable and allows processing entire code repositories or large technical specifications in a single pass.
The API is OpenAI-compatible and exposes parameters for "thinking mode" (deep reasoning), streaming, function calls, structured outputs, and context caching. A notable feature is "tool_stream," which streams tool-call arguments during function execution, reducing perceived latency.
For local deployment, Z.ai supports vLLM and SGLang, with a dedicated GitHub repository for deployment instructions. The Hugging Face model card also lists additional serving frameworks: xLLM, Transformers, and KTransformers.
The model size (754B) means full self-hosting requires significant infrastructure (multiple high-end GPUs). However, the MoE architecture with only 8 active experts per token makes inference more efficient than the raw size would suggest.
GLM-5.1 vs Claude Opus, GPT-5, and Gemini: Benchmark Comparison
Z.ai provides a detailed benchmark comparison table positioning GLM-5.1 against proprietary models and Chinese open-source competitors.
Benchmark | GLM-5.1 | Claude Opus 4 | GPT-5 | Gemini 3 Pro |
|---|---|---|---|---|
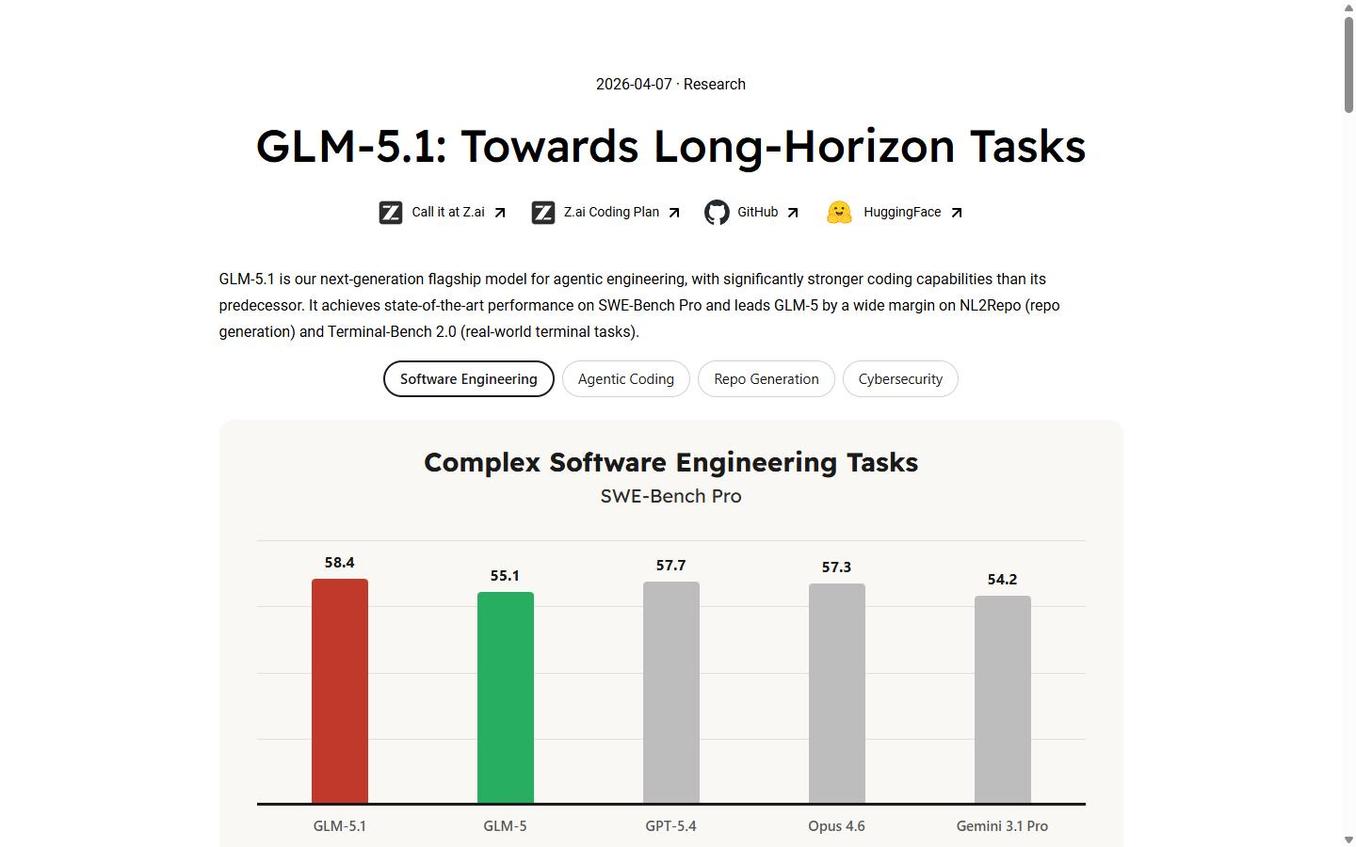
SWE-Bench Pro | 58.4 | 57.3 | 57.7 | — |
Terminal-Bench 2.0 | 63.5 | 65.4 | — | 68.5 |
NL2Repo | — | — | — | — |
HLE (reasoning) | 31.0 | — | 39.8 | 45.0 |
Autonomous execution | 8 hours | ~30 min | ~30 min | ~30 min |
License | MIT | Proprietary | Proprietary | Proprietary |
Parameters | 754B (MoE) | Undisclosed | Undisclosed | Undisclosed |
On SWE-Bench Pro (resolving bugs in real repositories), GLM-5.1 scores 58.4, ahead of GPT-5.4 (57.7), Claude Opus 4.6 (57.3), and DeepSeek-V3.2 (54.2). This is a remarkable result for an open-weight model.
On Terminal-Bench 2.0, the picture is more nuanced: GLM-5.1 scores 63.5, behind Gemini 3.1 Pro (68.5) and Claude Opus 4.6 (65.4). On NL2Repo (generating complete repositories from natural language descriptions), GLM-5.1 scores 42.7, well behind Claude Opus 4.6 (49.8).
In pure reasoning (HLE), GLM-5.1 posts 31.0, significantly below Gemini 3.1 Pro (45.0) and GPT-5.4 (39.8). This is not a dominant general reasoning model: its strength lies specifically in long-duration code and agent tasks.
Against Chinese competitors, GLM-5.1 compares to Qwen3.6-Plus, MiniMax M2.7, DeepSeek-V3.2, and Kimi K2.5. The landscape is competitive, but GLM-5.1 stands out through its unique positioning on long-duration workflows.
MIT License and Local Deployment: What It Means for Developers
The MIT license is the most permissive standard open-source license. Unlike Apache 2.0 (which requires license notices and patent clauses) or Llama/Qwen licenses (which add usage restrictions), MIT only requires preserving the copyright notice in redistributions. For commercial use, this is the maximum freedom possible.
The model is distributed on Hugging Face under the "zai-org" organization and on ModelScope. API access is available through api.z.ai and BigModel.cn, with announced compatibility with Claude Code and OpenClaw.
For enterprises, the combination of MIT + open weights + local deployment support (vLLM/SGLang) enables complete self-hosting in environments sensitive to intellectual property or confidentiality. You can run your code agents entirely on-premise, with no data leaving your network.
Z.ai's API pricing uses a "Coding Plan" system with quota multipliers: 3x during peak hours (2-6 PM UTC+8) and 2x off-peak, with a limited-time promotion to 1x off-peak through end of April. This time-slot pricing model is unusual but logical for long-duration agent workloads.
What Are the Real-World Use Cases for an 8-Hour AI Agent?
GLM-5.1's positioning on long-duration workflows opens specific use cases that standard LLMs cannot address effectively.
Code performance optimization is the most obvious case. Instead of asking a human to manually profile, analyze, and optimize a critical module, you can launch a GLM-5.1 agent that will iterate for hours, testing hundreds of different configurations and approaches. The VectorDBBench results show that this iterative approach can produce order-of-magnitude improvements.
Complex code generation is another natural use. With 200K tokens of context and 128K of output, the model can ingest complete technical specifications, existing code repositories, and generate entire modules with tests and documentation. The planning-execution-testing-optimization cycle naturally lends itself to this type of task.
Benchmark engineering and kernel optimization are domains where the ability to iterate over hundreds of rounds is particularly valuable. KernelBench-type problems require exactly this kind of systematic exploration.
Limitations exist: on general reasoning tasks (HLE, GPQA), GLM-5.1 is not the best choice. Its advantage concentrates on long-duration code and tooling tasks. For general conversations or pure scientific reasoning, other models remain better suited.
For DevOps and SRE teams, GLM-5.1's ability to maintain coherent context across thousands of tool calls opens interesting possibilities for complex pipeline automation. An agent could monitor a system, diagnose a performance issue, propose and test fixes, then validate the solution in production, all autonomously over several hours.
It is worth staying clear-eyed about the limitations, however. Self-hosting a 754 billion parameter model is not within everyone's reach. Even with the MoE architecture, you need multiple high-end GPUs to run the model locally. The Z.ai API is an alternative, but the time-slot pricing system adds planning complexity. And the general reasoning performance (HLE at 31.0) is a reminder that this is not a universal model.
The competitive landscape is also worth considering. In the Chinese open-model ecosystem, GLM-5.1 competes with Qwen3.6-Plus, MiniMax M2.7, DeepSeek-V3.2, and Kimi K2.5. Each has different strengths, but none match GLM-5.1's explicit focus on long-horizon autonomous work. In the proprietary space, Claude Opus 4.6 remains stronger on some coding benchmarks (NL2Repo at 49.8 vs 42.7), and Gemini 3.1 Pro leads on reasoning tasks. The choice depends entirely on whether your workload benefits from sustained iteration or one-shot quality.
For enterprises considering their AI agent strategy, the MIT license plus open weights plus local deployment path make GLM-5.1 worth serious evaluation for any workflow involving sustained autonomous coding. The ability to feed a 200K-token context with an entire codebase and specification, then let the agent iterate for hours with 128K tokens of output capacity, is a capability that simply did not exist in open-weight models before. Whether it replaces your current coding assistant depends on your workload: if you need quick one-shot answers, look elsewhere; if you need an AI that works a full shift without losing focus, GLM-5.1 is currently the strongest open contender.
The arrival of GLM-5.1 marks a turning point in how language models are evaluated. Rather than measuring intelligence on isolated questions only, Z.ai pushes the community to evaluate sustained productivity over hours of work. This is a perspective shift that better reflects the reality of complex software projects, and it places the bar exactly where AI agents will need to prove their value in the months ahead.
```

Klare, transparente Preise ohne versteckte Kosten.
Keine Verpflichtung, Preise, die Ihnen helfen, Ihre Akquise zu steigern.
Credits(optional)
Sie benötigen keine Credits, wenn Sie nur E-Mails senden oder auf LinkedIn-Aktionen ausführen möchten
Können verwendet werden für:
E-Mails finden
KI-Aktion
Nummern finden
E-Mails verifizieren
€19pro Monat
1,000
5,000
10,000
50,000
100,000
1,000 Gefundene E-Mails
1,000 KI-Aktionen
20 Nummern
4,000 Verifizierungen
€19pro Monat
Entdecken Sie andere Artikel, die Sie interessieren könnten!
Alle Artikel ansehenSoftware
Veröffentlicht am 14. Mai 2024
7 Alternativen zu Folderly, um Ihre Zustellbarkeit im Jahr 2026 zu verbessern
 Marie Head Of Sales
Marie Head Of SalesWeiterlesen
Blog
Veröffentlicht am 5. Apr. 2025
FullEnrich: Bewertungen, Preise und Alternativen, um böse Überraschungen zu vermeiden
 Mathieu Co-founder
Mathieu Co-founderWeiterlesen
Software
Veröffentlicht am 11. Juli 2024
7 Alternativen zu Expandi, um Ihre Akquisitionskosten zu senken
Marie Head Of SalesWeiterlesen
Software
Veröffentlicht am 22. Apr. 2024
Die 5 besten Alternativen zu Dropcontact für eine bessere B2B-Kundenakquise
Marie Head Of SalesWeiterlesen
Software
Veröffentlicht am 14. Juli 2024
6 Alternativen zu Skylead, um Kosten zu sparen und Ihre Lead-Generierung zu verbessern
Marie Head Of SalesWeiterlesen
Software
Veröffentlicht am 31. März 2025
9 Alternativen zu UpLead, um Ihre Kundenakquise WIRKLICH anzukurbeln
 Niels Co-founder
Niels Co-founderWeiterlesen
Made with ❤ for Growth Marketers by Growth Marketers
Copyright © 2026 Emelia All Rights Reserved