
Zurück zum Hub
Blog
KI
MiniMax M2.5: 20x Cheaper Than Claude and #1 on OpenClaw?
Veröffentlicht am 11. März 2026Aktualisiert am 27. Mai 2026
At Emelia, we use artificial intelligence every day to optimize B2B prospecting for our clients. At Bridgers, we build custom AI solutions for companies of all sizes. When a Chinese open source model starts rivaling the best proprietary models on the market at a fraction of the price, that is exactly the kind of disruption worth paying attention to. MiniMax M2.5 is reshaping the AI coding agent ecosystem, and here is why you should care.
What Is MiniMax M2.5 and Why Is Everyone Talking About It?
MiniMax M2.5 is an open source large language model (LLM) developed by MiniMax, a Shanghai-based Chinese AI company. Released on February 12, 2026, just weeks after the company's blockbuster Hong Kong IPO, it immediately made waves by delivering coding performance on par with the best proprietary models while being radically cheaper.
The model uses a Mixture-of-Experts (MoE) architecture with 230 billion total parameters, but only 10 billion active parameters per token, an activation ratio of just 4.3%. This ultra-lightweight design is what allows M2.5 to deliver frontier-level performance while remaining significantly faster and cheaper to operate than dense models of comparable intelligence. For context, GLM-5, another leading Chinese model released the same week, uses 744 billion total parameters with 40 billion active, making M2.5 the more efficient choice by a wide margin.
MiniMax M2.5 was trained using a proprietary reinforcement learning framework called Forge, powered by the CISPO algorithm, across more than 200,000 complex real-world environments. The training covers over 10 programming languages (Python, Go, C, C++, TypeScript, Rust, Kotlin, Java, JavaScript, PHP, Lua, Dart, Ruby, and more). It handles the full software development lifecycle: from zero-to-one system design and environment setup, through feature iteration and code review, all the way to comprehensive testing. The model ships in two variants: a standard version at 50 tokens/second and a Lightning version at 100 tokens/second, twice as fast as most frontier models.
What truly set the community on fire was the partnership between Ollama and MiniMax, announced on launch day. Ollama's tweet racked up over 435,000 impressions and 4,100 likes, offering free access to the model for several days.
Within weeks, MiniMax M2.5 became the most used model on OpenClaw, the popular AI coding agent. Developers worldwide are adopting it for daily workflows, and MiniMax even launched MaxClaw, an official integration between OpenClaw and M2.5.
MiniMax M2.5 vs Claude Opus: Benchmark Comparison
The numbers speak for themselves. On SWE-Bench Verified, the gold standard for evaluating bug-fixing capabilities on real GitHub projects, MiniMax M2.5 scores 80.2%. Claude Opus 4.6, Anthropic's flagship model, comes in at 80.8%. The gap is just 0.6 percentage points.
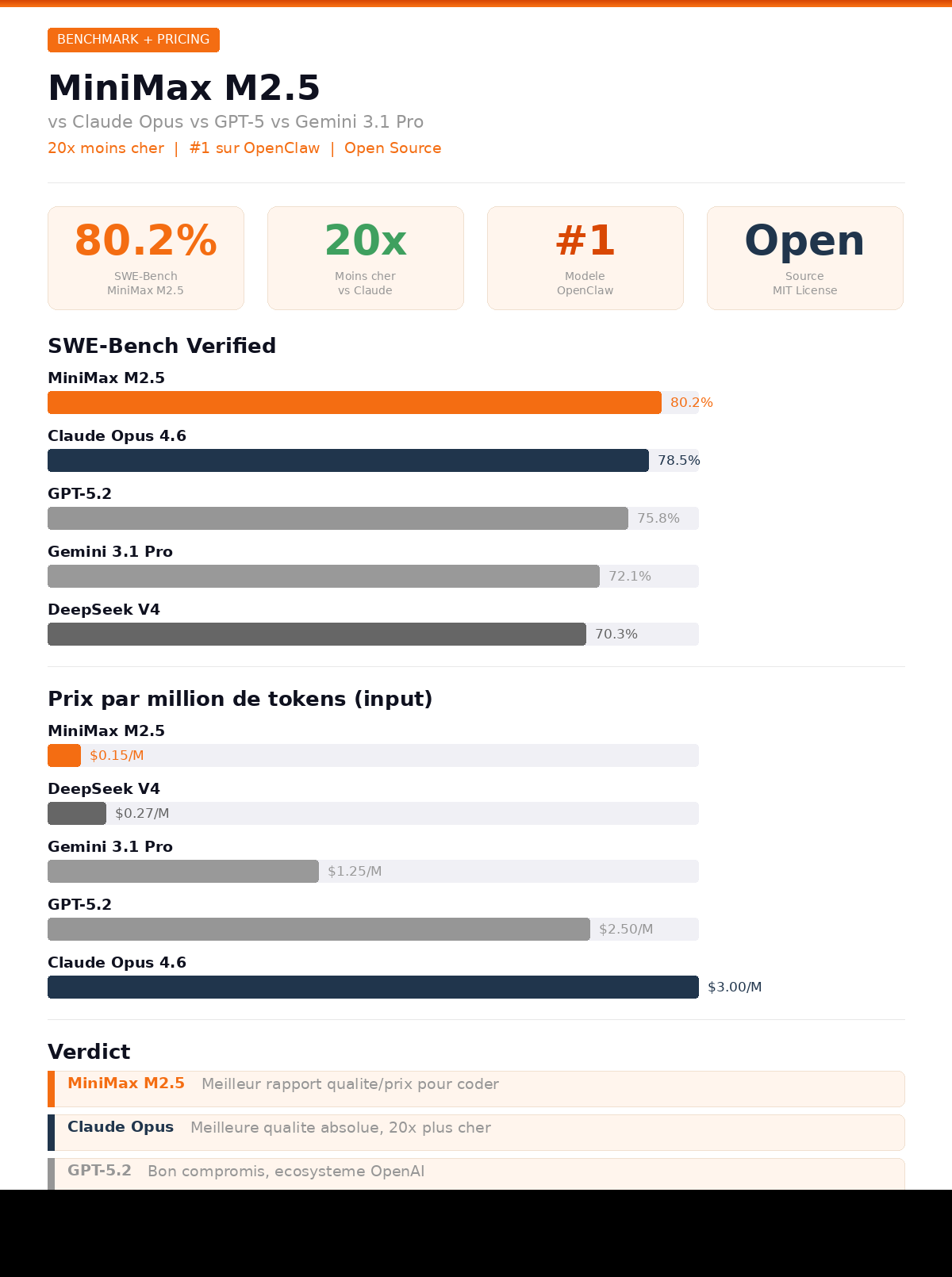
On Multi-SWE-Bench, which evaluates performance on more complex multi-file projects, M2.5 actually beats Opus with a score of 51.3% vs 50.3%. On the alternative scaffoldings Droid and OpenCode, M2.5 also edges ahead of Opus 4.6: 79.7% vs 78.9% on Droid, and 76.1% vs 75.9% on OpenCode.
In terms of speed, M2.5 cut its average execution time per SWE-Bench task from 31.3 minutes (M2.1) down to 22.8 minutes, a 37% improvement. This is virtually identical to Claude Opus 4.6's 22.9 minutes. And the model consumes fewer tokens per task: 3.52 million vs 3.72 million for M2.1.
Beyond coding, M2.5 posts strong reasoning scores: 86.3% on AIME25, 85.2% on GPQA-D, and 76.3% on BrowseComp for agentic search tasks.
Here is the full comparison of the main models:
Feature | MiniMax M2.5 | Claude Opus 4.6 | GPT-5.2 | Gemini 3.1 Pro |
|---|---|---|---|---|
SWE-Bench Verified | 80.2% | 80.8% | 80.0% | 78.0% |
Multi-SWE-Bench | 51.3% | 50.3% | 49.1% | 42.7% |
Input price (per M tokens) | $0.15 (std) / $0.30 (Lightning) | $5.00 | $1.75 | $2.00 |
Output price (per M tokens) | $1.20 (std) / $2.40 (Lightning) | $25.00 | $14.00 | $12.00 |
Open source | Yes (modified MIT) | No | No | No |
Ollama support | Yes (native) | No | No | No |
Context window | 1M tokens (API) / 205K (local) | 200K (1M in beta) | 128K | 1M |
Speed | 50-100 TPS | ~60 TPS | ~80 TPS | ~70 TPS |
Total parameters | 230B (10B active) | Undisclosed | Undisclosed | Undisclosed |
MiniMax M2.5 Pricing: 20x Cheaper Than Claude
This is arguably MiniMax M2.5's most compelling argument: the price-to-performance ratio. According to official MiniMax data, the cost per task on SWE-Bench Verified is only 10% of Claude Opus 4.6's cost. In terms of output price per million tokens, you go from $25 for Opus down to $1.20 for M2.5 standard, a factor of more than 20x. Even against GPT-5.2 ($14 per million output tokens) and Gemini 3.1 Pro ($12 per million output tokens), M2.5 remains dramatically cheaper.
To put this in concrete terms: for a daily workload of 10 million input tokens and 2 million output tokens, M2.5 costs approximately $4.70 per day compared to roughly $100 per day for Opus. Over a working month, that is nearly $2,000 in savings. One real-world test by a developer running a 1-2 hour coding session found that M2.5 consumed about 17 million tokens for around $1.20, while Claude Opus 4.6 consumed about 1.47 million tokens for around $7.58. MiniMax uses more tokens per session because it thinks through problems more verbosely, but the final bill is still a fraction of the competition.
MiniMax puts it simply: it costs just $1 to run the model continuously for one hour at 100 tokens per second. At 50 tokens per second, the cost drops to $0.30.
MiniMax also offers a dedicated "Coding Plan" starting at $10 per month for 100 prompts per 5-hour window, and a Coding Plus plan at $20 per month for 300 prompts per 5-hour window. Alibaba even offers a Coding Plan at $3 per month that provides access to MiniMax M2.5, Kimi K2.5, GLM-5, and Qwen 3.5-Plus through a single API key.
How to Use MiniMax M2.5 with OpenClaw and Ollama
One of MiniMax M2.5's biggest advantages is how easy it is to integrate. Thanks to the Ollama partnership, you can use the model with just a few commands, no complex configuration, no MCP servers to install, no API keys to manage.
Via Ollama Cloud
To use MiniMax M2.5 directly through Ollama's cloud:
Chat mode: ollama run minimax-m2.5:cloud
With OpenClaw: ollama launch openclaw --model minimax-m2.5:cloud
With Claude Code: ollama launch claude --model minimax-m2.5:cloud
With Codex: ollama launch codex --model minimax-m2.5:cloud
With OpenCode: ollama launch opencode --model minimax-m2.5:cloud
Running locally
Model weights are available on HuggingFace. MiniMax recommends SGLang or vLLM for optimal performance. However, with 230 billion total parameters, you need serious hardware: at minimum a GPU cluster with 192 GB of VRAM. Quantized GGUF versions are available for more accessible deployment, but with a context window limited to roughly 196K tokens.
Via MaxClaw
MiniMax launched MaxClaw, an official integration between OpenClaw and MiniMax Agent, powered by M2.5. MaxClaw runs 24/7 across Telegram, WhatsApp, Slack, and Discord, with an ecosystem of over 10,000 pre-built expert agents. Pricing starts at $19 per month.
Recommended parameters
For best results, MiniMax recommends: temperature=1.0, top_p=0.95, top_k=40.
MiniMax: The Chinese Company Challenging AI Giants
MiniMax was founded in 2021 in Shanghai by Yan Junjie, a 36-year-old former executive at SenseTime. An avid gamer, Yan became fascinated with OpenAI in 2019 after its bots defeated the world's best human teams at Dota 2. That fascination led him to pivot from computer vision to natural language processing.
MiniMax's early days were rough. Yan describes the first three years as "pure agony," in a landscape where most Chinese AI startups were chasing ChatGPT clones. MiniMax instead chose to build a single multimodal model capable of processing text, audio, image, video, and music.
The bet paid off. In January 2026, MiniMax completed its Hong Kong IPO, raising $618 million with shares priced at the top of the range at HK$165 each. The company was valued at approximately $6.5 billion, and Yan Junjie became a billionaire at 36 with an estimated net worth of $3.2 billion.
Notable investors include Alibaba, Tencent, the Abu Dhabi Investment Authority, Hillhouse Investment, and miHoYo (the creators of Genshin Impact, whose co-founder Liu Wei serves on MiniMax's board). In 2026, revenue more than doubled to $79 million, though losses widened to $1.87 billion due to heavy R&D spending.
MiniMax now counts over 212 million cumulative users. Yan's vision is clear: make AI accessible to everyone. "As AI capabilities continue to scale, we have to ask: will these models be concentrated among a select few at a prohibitive $1,000 monthly premium, or will they be accessible to the masses at a $20 price point?" he has stated. With M2.5, the answer seems to lean decisively toward the latter.
Is MiniMax M2.5 the Best Open Source Coding Model in 2026?
That is the question everyone is asking. And the signals are strong. MiniMax M2.5 stands out through several unique characteristics in the open source ecosystem:
Architect-level planning. Unlike most models that generate code line by line, M2.5 developed a "spec-writing" behavior during training: before writing any code, it decomposes and plans features, structure, and UI design from the perspective of an experienced software architect.
Full-stack coverage. The model handles full-stack projects across multiple platforms: Web, Android, iOS, Windows, and Mac, encompassing server-side APIs, business logic, databases, and more. Not just frontend demos.
Internal productivity. MiniMax claims that 80% of its newly committed code is generated by M2.5, and 30% of company tasks are completed autonomously by the model.
Massive adoption. Developer Pratham (448,000 followers) sums up community sentiment: "MiniMax M2.5 > Claude Opus 4.6. I have been using it for a couple of days and have never hit the limit."
Notion has also integrated MiniMax M2.5 as the first open-weight model in its Custom Agents. Akshay Kothari, Notion's co-founder, noted that for simpler tasks, the model is "a lot cheaper than other models."
Real-world use cases
For indie developers and startups: You can now run a high-performance coding agent for $10 per month instead of $200-400 with Claude Opus. This is a fundamental shift for tight budgets.
For engineering teams: OpenClaw + MiniMax M2.5 enables automated code review, bug resolution, and testing at scale without blowing up API costs.
For enterprises: Automated generation of Word documents, PowerPoint presentations, and Excel financial models, with a 59% win rate against mainstream models according to MiniMax's internal tests.
For prospecting and marketing: At Emelia, integrating powerful yet affordable models like M2.5 into automation workflows opens new possibilities for large-scale personalization of prospecting campaigns.
MiniMax M2.5 Limitations
Let us be honest: MiniMax M2.5 is not perfect, and it is important to understand its weaknesses before adopting it.
Output quality trails Opus on complex tasks. Multiple users report that while M2.5 shines on benchmarks, real-world code quality on complex, non-standard projects falls below Claude Opus 4.6. One tester noted: "MiniMax is not close to Opus in output quality, but Opus is extremely expensive."
No multimodality. Unlike GPT-5.2 and Gemini 3.1 Pro, M2.5 is a text-only model (with image input support). It cannot process videos, complex diagrams, or generate images.
Occasional logic errors. One-shot generated code can contain functional errors such as logic inconsistencies, particularly in complex animations and interactions.
Limited context window locally. While the MiniMax API advertises 1 million tokens, local deployments via GGUF are limited to roughly 196K tokens.
Modified MIT license. Commercial use is permitted, but you must display the "MiniMax M2.5" credit in your product.
General reasoning. On pure reasoning benchmarks (outside code), M2.5 falls below frontier models like GPT-5.2 and Gemini 3.1 Pro. Its Artificial Analysis Intelligence Index score is 42, above average but behind the leaders.
Local inference speed. Several testers note that M2.5 is slower than GLM-5 and Gemini 3 Deep Think at generating responses, particularly due to extended thinking and reasoning time.
Who Is MiniMax M2.5 For?
You should try it if:
You use AI coding agents (OpenClaw, Claude Code, Codex, OpenCode) and want to cut costs by 90%
You are an indie developer or startup on a tight budget
You want a high-performance open source model for full-stack coding
You want a model that works natively with Ollama
You can skip it if:
Absolute code quality is your top priority and budget is not a concern
You need multimodality (video, images, diagrams)
Your tasks primarily involve general reasoning rather than coding
You prefer not to rely on a Chinese model for compliance or preference reasons
The Bigger Picture: Why Is a Chinese Model Dominating the Coding Agent Ecosystem?
The rise of MiniMax M2.5 is not an isolated event. It is part of a broader trend: Chinese AI labs are producing open source models that match or exceed Western proprietary alternatives at a fraction of the cost. In February 2026 alone, alongside M2.5, Zhipu released GLM-5 (744B parameters), Moonshot launched Kimi K2.5, and Alibaba created a unified coding plan giving developers access to all these models for just $3 per month.
This matters because the economics of AI development are shifting. When frontier coding intelligence costs $0.15 per million input tokens instead of $5, it changes who can build with AI and what they can build. Independent developers, bootstrapped startups, and teams in emerging markets suddenly have access to the same coding capabilities that previously required enterprise-level API budgets.
The developer community has noticed. On PinchBench, which benchmarks LLMs as real OpenClaw coding agents across success rate, speed, and cost, open source models occupy the most attractive quadrant. MiniMax M2.5, DeepSeek V3.2, and Kimi K2.5 all deliver high success rates at low cost.
For Western model providers, the message is clear: performance alone is no longer enough. Price-performance is the new frontier.
The Bottom Line
MiniMax M2.5 represents a turning point in the AI ecosystem. For the first time, a Chinese open source model directly rivals the best American proprietary models on coding tasks while being 10 to 20 times cheaper. The fact that Notion adopted it, Ollama forged an official partnership, and it became the most used model on OpenClaw in barely a month shows the disruption is very real.
MiniMax is not resting either. Over the three and a half months from late October 2026 to February 2026, the company released M2, M2.1, and M2.5 in rapid succession. Their rate of improvement on SWE-Bench Verified has outpaced the Claude, GPT, and Gemini model families. If this trajectory holds, M2.5 may be just the beginning.
The question is no longer whether open source models can compete with proprietary ones. The question is now: why are you still paying 20 times more?

Klare, transparente Preise ohne versteckte Kosten.
Keine Verpflichtung, Preise, die Ihnen helfen, Ihre Akquise zu steigern.
Credits(optional)
Sie benötigen keine Credits, wenn Sie nur E-Mails senden oder auf LinkedIn-Aktionen ausführen möchten
Können verwendet werden für:
E-Mails finden
KI-Aktion
Nummern finden
E-Mails verifizieren
€19pro Monat
1,000
5,000
10,000
50,000
100,000
1,000 Gefundene E-Mails
1,000 KI-Aktionen
20 Nummern
4,000 Verifizierungen
€19pro Monat
Entdecken Sie andere Artikel, die Sie interessieren könnten!
Alle Artikel ansehenBlog
Veröffentlicht am 5. Apr. 2025
FullEnrich: Bewertungen, Preise und Alternativen, um böse Überraschungen zu vermeiden
 Mathieu Co-founder
Mathieu Co-founderWeiterlesen
Software
Veröffentlicht am 11. Juli 2024
7 Alternativen zu Expandi, um Ihre Akquisitionskosten zu senken
 Marie Head Of Sales
Marie Head Of SalesWeiterlesen
Software
Veröffentlicht am 22. Apr. 2024
Die 5 besten Alternativen zu Dropcontact für eine bessere B2B-Kundenakquise
Marie Head Of SalesWeiterlesen
Software
Veröffentlicht am 4. Juni 2024
Die 6 besten Alternativen zu GetProspect, um Ihre Kundenakquise anzukurbeln
Marie Head Of SalesWeiterlesen
Software
Veröffentlicht am 31. März 2025
9 Alternativen zu UpLead, um Ihre Kundenakquise WIRKLICH anzukurbeln
 Niels Co-founder
Niels Co-founderWeiterlesen
Software
Veröffentlicht am 26. Apr. 2024
Email Finder 2026: Die 9 besten Hunter.io-Alternativen
Marie Head Of SalesWeiterlesen
Made with ❤ for Growth Marketers by Growth Marketers
Copyright © 2026 Emelia All Rights Reserved