
GLM-5.1 : le LLM Open Source Qui Code 8 Heures Sans Interruption (Test et Analyse)
Publié le 11 avr. 2026Mis à jour le 13 avr. 2026
Z.ai (anciennement Zhipu AI) vient de publier GLM-5.1, un modèle de langage de 754 milliards de paramètres distribué sous licence MIT, avec une promesse qui le distingue de tous ses concurrents : il peut travailler de manière autonome sur une seule tâche pendant 8 heures. Pas 8 minutes. Pas 8 conversations. Huit heures de planification, exécution, optimisation itérative et livraison, avec des centaines de rounds et des milliers d'appels d'outils.
C'est un changement de paradigme. La plupart des LLM actuels, même les meilleurs, sont évalués sur des tâches courtes : résoudre un problème, générer un fichier, répondre à une question. GLM-5.1 est conçu pour un usage radicalement différent. Il est pensé comme un agent d'ingénierie logicielle qui reste concentré et s'améliore au fil du temps, plutôt que de plafonner après quelques itérations.
Z.ai est une entreprise basée à Pékin, issue de la recherche de l'université Tsinghua. Ses fondateurs, les professeurs Tang Jie et Li Juanzi, sont des figures reconnues de la recherche en IA chinoise. L'entreprise est dirigée par le CEO Zhang Peng. Avec GLM-5.1, Z.ai entre dans la course aux modèles ouverts avec un positionnement agressif : licence MIT (plus permissive qu'Apache 2.0), poids ouverts sur Hugging Face et ModelScope, et compatibilité avec les outils populaires comme Claude Code et OpenClaw.
Comment fonctionne l'exécution autonome de 8 heures de GLM-5.1 ?
Le concept central de GLM-5.1 repose sur ce que Z.ai appelle "l'ingénierie agentique". Au lieu de traiter chaque requête comme une interaction isolée, le modèle maintient un cycle continu : expérimenter, analyser, optimiser, et recommencer. Il peut itérer sur des centaines de rounds avec des milliers d'appels d'outils avant de livrer un résultat final.
La documentation officielle décrit le workflow en quatre phases : planification, exécution, optimisation itérative et livraison. Le modèle ne se contente pas de générer du code puis de s'arrêter. Il exécute ses propres tests, analyse les résultats, identifie les faiblesses et relance un cycle d'optimisation.
Pour illustrer ce concept, Z.ai fournit un exemple concret sur VectorDBBench (benchmark de bases de données vectorielles). Sur le dataset SIFT-1M avec un rappel supérieur ou égal à 95 %, GLM-5.1 a atteint 21 500 QPS (requêtes par seconde) après plus de 600 itérations et 6 000 appels d'outils. À titre de comparaison, le meilleur résultat précédent en 50 tours avait été obtenu par Claude Opus 4.6 avec 3 547 QPS.
Un autre exemple : sur KernelBench Level 3 (50 problèmes d'optimisation de kernels), GLM-5.1 atteint un speedup géométrique moyen de 3,6x par rapport au baseline PyTorch eager. En comparaison, torch.compile standard fait 1,15x et max-autotune 1,49x. Claude Opus 4.6 atteint 4,2x, mais sur un nombre d'itérations limité.
Ce qui distingue GLM-5.1 n'est pas qu'il soit toujours le meilleur sur un benchmark ponctuel, mais qu'il continue à s'améliorer là où les autres plafonnent. La courbe de performance ne s'aplatit pas après quelques tours.
Architecture technique : 754B paramètres, MoE et contexte 200K
GLM-5.1 est un modèle massif de 754 milliards de paramètres. Il utilise une architecture Mixture-of-Experts (MoE) avec un design spécifique décrit comme "glm_moe_dsa", qui intègre du Multi-Latent Attention (MLA, style DeepSeek) et du Dynamic Sparse Attention.
La configuration MoE comprend 256 experts routés avec 8 actifs par token, ce qui permet un calcul efficace malgré la taille totale du modèle. Le contexte est fixé à 200K tokens avec une capacité de sortie allant jusqu'à 128K tokens, ce qui est considérable et permet de traiter des repositories de code entiers ou des spécifications techniques volumineuses en une seule passe.
L'API est compatible OpenAI et expose des paramètres pour le "thinking mode" (réflexion profonde), le streaming, les appels de fonctions, les sorties structurées et le caching de contexte. Une fonctionnalité notable est le "tool_stream", qui permet de streamer les arguments d'appels d'outils pendant l'exécution des fonctions, réduisant la latence perçue.
Pour le déploiement local, Z.ai supporte vLLM et SGLang, avec un repository GitHub dédié aux instructions de déploiement. La carte modèle sur Hugging Face liste aussi des frameworks supplémentaires : xLLM, Transformers et KTransformers.
La taille du modèle (754B) signifie que l'auto-hébergement complet nécessite une infrastructure significative (plusieurs GPU haut de gamme). Cependant, l'architecture MoE avec seulement 8 experts actifs par token rend l'inférence plus efficace que ce que la taille brute laisserait penser.
GLM-5.1 vs Claude Opus, GPT-5 et Gemini : les benchmarks comparés
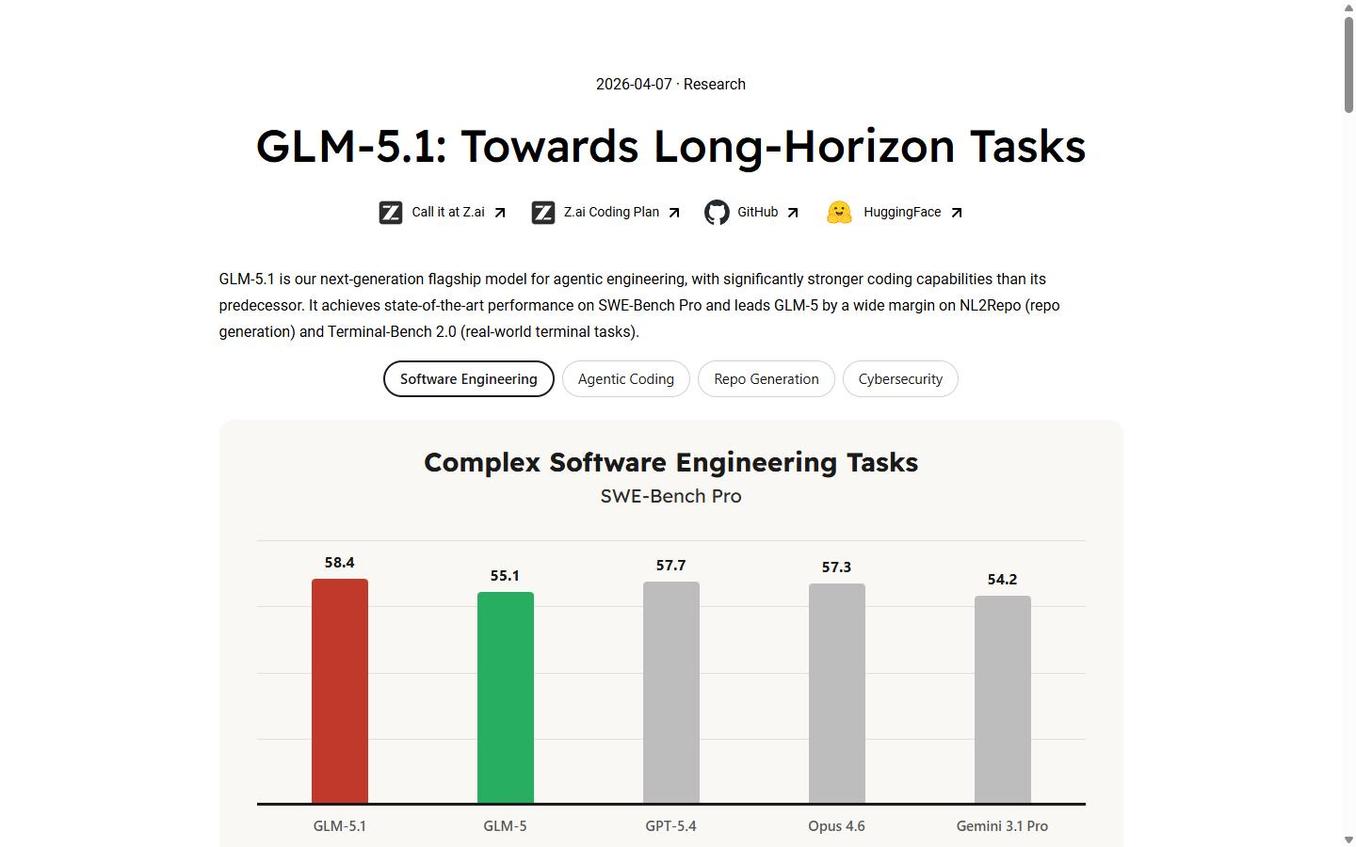
Z.ai fournit un tableau de benchmarks comparatif détaillé qui positionne GLM-5.1 face aux modèles propriétaires et aux concurrents open-source chinois.
Benchmark | GLM-5.1 | Claude Opus 4 | GPT-5 | Gemini 3 Pro |
|---|---|---|---|---|
SWE-Bench Pro | 58,4 | 57,3 | 57,7 | — |
Terminal-Bench 2.0 | 63,5 | 65,4 | — | 68,5 |
NL2Repo | — | — | — | — |
HLE (raisonnement) | 31,0 | — | 39,8 | 45,0 |
Exécution autonome | 8 heures | ~30 min | ~30 min | ~30 min |
Licence | MIT | Propriétaire | Propriétaire | Propriétaire |
Paramètres | 754B (MoE) | Non divulgué | Non divulgué | Non divulgué |
Sur SWE-Bench Pro (résolution de bugs dans des repos réels), GLM-5.1 atteint 58,4, devançant GPT-5.4 (57,7), Claude Opus 4.6 (57,3) et DeepSeek-V3.2 (54,2). C'est un résultat remarquable pour un modèle open-weight.
Sur Terminal-Bench 2.0, le tableau est plus nuancé : GLM-5.1 obtient 63,5, derrière Gemini 3.1 Pro (68,5) et Claude Opus 4.6 (65,4). Sur NL2Repo (génération de dépôts complets à partir de descriptions en langage naturel), GLM-5.1 score 42,7, loin derrière Claude Opus 4.6 (49,8).
En raisonnement pur (HLE), GLM-5.1 affiche 31,0, nettement en dessous de Gemini 3.1 Pro (45,0) et GPT-5.4 (39,8). Ce n'est pas un modèle de raisonnement général dominant : sa force est spécifiquement dans les tâches de code et d'agent sur longue durée.
Face aux concurrents chinois, GLM-5.1 se compare à Qwen3.6-Plus, MiniMax M2.7, DeepSeek-V3.2 et Kimi K2.5. Le paysage est compétitif, mais GLM-5.1 se distingue par son positionnement unique sur les workflows de longue durée.
Licence MIT et déploiement local : ce que ça change pour les développeurs
La licence MIT est la plus permissive des licences open-source standard. Contrairement à Apache 2.0 (qui impose une mention de licence et une clause de brevets) ou aux licences Llama/Qwen (qui ajoutent des restrictions d'usage), MIT ne demande que la conservation du copyright dans les redistributions. Pour un usage commercial, c'est le maximum de liberté possible.
Le modèle est distribué sur Hugging Face sous l'organisation "zai-org" et sur ModelScope. L'accès API est disponible via api.z.ai et BigModel.cn, avec une compatibilité annoncée avec Claude Code et OpenClaw.
Pour les entreprises, la combinaison MIT + poids ouverts + support de déploiement local (vLLM/SGLang) permet un self-hosting complet dans des environnements sensibles en termes de propriété intellectuelle ou de confidentialité. Vous pouvez faire tourner vos agents de code entièrement dans vos locaux, sans qu'aucune donnée ne quitte votre réseau.
Le pricing de l'API Z.ai utilise un système de "Coding Plan" avec des multiplicateurs de quota : 3x pendant les heures de pointe (14h-18h UTC+8) et 2x en heures creuses, avec une promotion temporaire à 1x en heures creuses jusqu'à fin avril. Ce modèle de tarification par slots horaires est inhabituel mais logique pour des workloads d'agent de longue durée.
Quels cas d'usage concrets pour un agent IA de 8 heures ?
Le positionnement de GLM-5.1 sur les workflows de longue durée ouvre des cas d'usage spécifiques que les LLM standard ne peuvent pas adresser efficacement.
L'optimisation de performance de code est le cas le plus évident. Au lieu de demander à un humain de profiler, analyser et optimiser manuellement un module critique, vous pouvez lancer un agent GLM-5.1 qui va itérer pendant des heures, testant des centaines de configurations et approches différentes. Les résultats sur VectorDBBench montrent que cette approche itérative peut produire des améliorations d'un ordre de grandeur.
La génération de code complexe est un autre usage naturel. Avec 200K tokens de contexte et 128K de sortie, le modèle peut ingérer des spécifications techniques complètes, des repos de code existants, et générer des modules entiers avec tests et documentation. Le cycle planification-exécution-test-optimisation se prête naturellement à ce type de tâche.
L'ingénierie de benchmarks et l'optimisation de kernels sont des domaines où la capacité à itérer sur des centaines de rounds est particulièrement précieuse. Les problèmes de type KernelBench nécessitent exactement ce type d'exploration systématique.
Les limites existent : sur les tâches de raisonnement général (HLE, GPQA), GLM-5.1 n'est pas le meilleur choix. Son avantage se concentre sur les tâches de code et d'outillage de longue durée. Pour les conversations générales ou le raisonnement scientifique pur, d'autres modèles restent plus adaptés.
Pour les équipes DevOps et SRE, la capacité de GLM-5.1 à maintenir un contexte cohérent sur des milliers d'appels d'outils ouvre des possibilités intéressantes pour l'automatisation de pipelines complexes. Un agent pourrait surveiller un système de monitoring, diagnostiquer un problème de performance, proposer et tester des corrections, puis valider le fix en production, le tout de manière autonome sur plusieurs heures.
Il faut cependant rester lucide sur les limites. L'auto-hébergement d'un modèle de 754 milliards de paramètres n'est pas à la portée de tous. Même avec l'architecture MoE, il faut plusieurs GPU haut de gamme pour faire tourner le modèle en local. L'API Z.ai est une alternative, mais le système de pricing par slots horaires ajoute une complexité de planification. Et les performances en raisonnement général (HLE à 31,0) rappellent que ce n'est pas un modèle universel.
L'arrivée de GLM-5.1 marque un tournant dans l'évaluation des modèles de langage. Plutôt que de mesurer uniquement l'intelligence sur une question isolée, Z.ai pousse la communauté à évaluer la productivité soutenue sur des heures de travail. C'est un changement de perspective qui reflète mieux la réalité des projets logiciels complexes, et qui place le curseur exactement là où les agents IA vont devoir prouver leur valeur dans les mois à venir.

Des prix clairs, transparents et sans frais cachés.
Aucun engagement, des prix pour vous aider à augmenter votre prospection.
Crédits(optionnel)
Vous n'avez pas besoin de crédits si vous voulez simplement envoyer des emails ou faire des actions sur LinkedIn
Peuvent être utilisés pour :
Trouver Emails
Action IA
Trouver des Numéros
Vérifier des Emails
19€par mois
1 000
5 000
10 000
50 000
100 000
1 000 Emails trouvés
1 000 IA Actions
20 Numéros
4 000 Vérifications
19€par mois
Découvrez d'autres articles qui pourraient vous intéresser !
Voir tous les articlesLogiciels
Publié le 16 juin 2025
Alternatives à Google : 5 moteurs de recherche qui révolutionnent le web en 2026
 Mathieu Co-founder
Mathieu Co-founderLire la suite
IA
Publié le 11 avr. 2025
Cognism vs Waalaxy vs Emelia
 Niels Co-founder
Niels Co-founderLire la suite
IA
Publié le 18 juin 2025
Les 6 meilleurs assistants de réunions IA en 2026
Mathieu Co-founderLire la suite
Blog
Publié le 21 mai 2025
Les 7 Meilleures Applications de Suivi du Temps pour Booster Votre Productivité
Niels Co-founderLire la suite
Blog
Publié le 18 juin 2025
Les 5 meilleures applications de minuterie Pomodoro
Niels Co-founderLire la suite
LinkedIn
Publié le 20 mai 2025
Rechercher un numéro de téléphone : 7 méthodes qui marchent (2026)
 Marie Head Of Sales
Marie Head Of SalesLire la suite
Liens utiles
HubCold-email: Guide CompletDélivrabilité: Guide completAlternative à LemlistAPIDemander une démoProgramme d'affiliationFind emailConsultingA propos
Politique de confidentialitéCGVMentions légalesTestimonialsRoadmapAlternativesComparaisonsContactMade with ❤ for Growth Marketers by Growth Marketers
Copyright © 2026 Emelia All Rights Reserved