Back to hub
Blog
AI
Gemini 3.1 Flash-Lite Review: Full Test (2026)
Published on Mar 9, 2026Updated on May 27, 2026
At Emelia, we process millions of B2B prospecting data points every day - contact enrichment, lead classification, personalized email generation. The cost of AI APIs is a critical strategic concern for our platform. It's also a key topic for Bridgers Agency, which helps clients select the most cost-effective AI infrastructure. When Google announces a model at $0.25 per million input tokens, it warrants a thorough analysis.
What Is Gemini 3.1 Flash-Lite?
On March 3, 2026, Google launched Gemini 3.1 Flash-Lite, the fastest and most affordable model in the Gemini 3 series. Designed for high-volume workloads, it targets developers and enterprises that need to process millions of daily requests without blowing their budget. It is the third Gemini release in just three weeks, following Gemini 3.1 Pro and Gemini 3 Flash, signaling Google's aggressive push to dominate every tier of the AI model market.
Unlike flagship models such as Gemini 3.1 Pro, Flash-Lite is not built for complex reasoning or advanced creative generation. Its sweet spot is massive translation, content classification, moderation, structured data extraction, and repetitive agentic tasks. In other words, everything that demands speed, reliability, and minimal cost per token.
The model is based on the Gemini 3 Pro architecture but distilled and optimized for throughput. It was trained on Google's Tensor Processing Units (TPUs) using JAX and ML Pathways, and is natively multimodal - accepting text, images, audio, and video as inputs. It is currently available in preview through the Gemini API in Google AI Studio and via Vertex AI for enterprise customers.
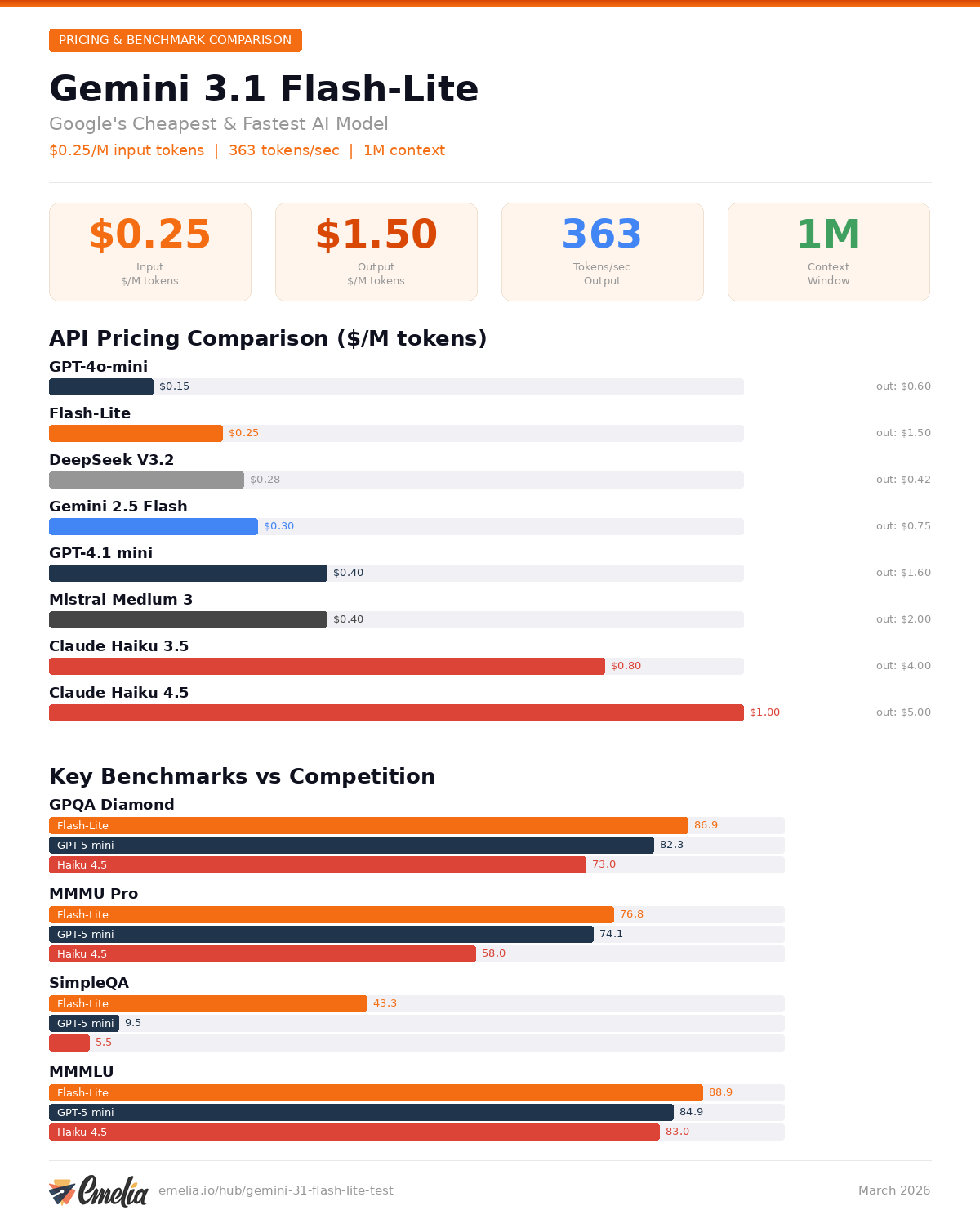
Gemini 3.1 Flash-Lite Pricing and Costs
Flash-Lite's pricing is aggressive. Here is the official rate:
Input tokens: $0.25 per million tokens
Output tokens: $1.50 per million tokens
Blended price (3:1 input/output ratio): approximately $0.56 per million tokens
At this price point, Flash-Lite positions itself as one of the cheapest proprietary models on the market. It is 8 times less expensive than Gemini 3.1 Pro ($2.00/M input) and up to 16 times cheaper for long contexts exceeding 200,000 tokens.
AI API Pricing Comparison Table 2026
Model | Input ($/M tokens) | Output ($/M tokens) | Provider |
|---|---|---|---|
Gemini 3.1 Flash-Lite | 0.25 | 1.50 | |
GPT-4o-mini | 0.15 | 0.60 | OpenAI |
GPT-5 mini | 0.25 | 2.00 | OpenAI |
DeepSeek V3.2 | 0.28 | 0.42 | DeepSeek |
Grok 4.1 Fast | 0.20 | 0.50 | xAI |
Claude Haiku 3.5 | 0.80 | 4.00 | Anthropic |
Claude Haiku 4.5 | 1.00 | 5.00 | Anthropic |
GPT-4.1 mini | 0.40 | 1.60 | OpenAI |
Gemini 2.5 Flash | 0.30 | 0.75 | |
Mistral Medium 3 | 0.40 | 2.00 | Mistral AI |
In terms of value for money, Flash-Lite significantly outperforms Claude Haiku 3.5 (3.2 times more expensive on input) and Claude Haiku 4.5 (4 times more expensive). Compared to GPT-4o-mini, Google's model is slightly pricier on input but offers a context window 8 times larger (1 million vs 128,000 tokens) and superior performance on most benchmarks.
Gemini 3.1 Flash-Lite Benchmarks vs GPT and Claude
The official numbers published by Google DeepMind are impressive for a model in this price tier. Flash-Lite doesn't just settle for being cheap - it competes directly with far more expensive models.
Benchmark Comparison Table
Benchmark | Gemini 3.1 Flash-Lite | GPT-5 mini | Claude 4.5 Haiku | Grok 4.1 Fast | Gemini 2.5 Flash |
|---|---|---|---|---|---|
Elo Arena.ai | 1432 | - | - | - | - |
GPQA Diamond | 86.9% | 82.3% | 73.0% | 84.3% | 82.8% |
MMMU Pro | 76.8% | 74.1% | 58.0% | 63.0% | 66.7% |
Video-MMMU | 84.8% | 82.5% | - | 74.6% | 79.2% |
MMMLU (multilingual) | 88.9% | 84.9% | 83.0% | 86.8% | 86.6% |
SimpleQA Verified | 43.3% | 9.5% | 5.5% | 19.5% | 28.1% |
LiveCodeBench | 72.0% | 80.4% | 53.2% | 76.5% | 62.6% |
Humanity's Last Exam | 16.0% | 16.7% | 9.7% | 17.6% | 11.0% |
MRCR v2 128k | 60.1% | 52.5% | 35.3% | 54.6% | 54.3% |
Several takeaways stand out. Flash-Lite dominates on scientific knowledge benchmarks (GPQA Diamond at 86.9%), multimodal understanding (MMMU Pro at 76.8%), and video processing (Video-MMMU at 84.8%). It even surpasses Gemini 2.5 Flash on nearly all metrics, which is remarkable for a "Lite" model.
On parametric factuality (SimpleQA), the gap is striking: 43.3% versus only 9.5% for GPT-5 mini. For applications where factual accuracy is critical, this is a decisive advantage.
The only area where Flash-Lite loses ground is code generation: 72.0% on LiveCodeBench versus 80.4% for GPT-5 mini. If your primary use case is code generation, GPT-5 mini remains the stronger choice.
Speed and Latency: The Numbers That Change Everything
Speed is Flash-Lite's killer argument. According to Artificial Analysis benchmarks:
Time to first token (TTFT): 2.5 times faster than Gemini 2.5 Flash
Output speed: 363 tokens per second, a 45% improvement over Gemini 2.5 Flash (249 tokens/s)
Overall latency: optimized for high-frequency workflows
These numbers matter because latency directly impacts user experience and cost. A model that responds 2.5 times faster means your application can serve more users on the same infrastructure. At 363 tokens per second, Flash-Lite can generate a full 500-word response in roughly four seconds, making it viable for real-time conversational interfaces.
For a SaaS application that needs real-time response - like a prospecting tool enriching contact records on the fly or a chatbot handling hundreds of simultaneous conversations - this speed difference translates directly into better user experience and reduced infrastructure costs. Google positions Flash-Lite as the "reflexes" in a cascading architecture, handling the fast execution while Pro models handle the deep thinking.
Best Use Cases for Gemini Flash-Lite
Flash-Lite excels in scenarios where volume and speed matter more than depth of reasoning. Here are the use cases where this model shines:
Large-scale translation: with an MMMLU score of 88.9%, Flash-Lite handles multilingual tasks remarkably well. Ideal for translating millions of product listings or marketing content.
Content classification and sorting: content moderation, lead categorization, sentiment analysis. Early testers report 94 to 97% compliance rates on structured outputs.
Structured data extraction: converting unstructured documents into JSON, CSV, or other machine-readable formats, with 100% consistency on tagging tasks reported by HubX.
High-volume agentic tasks: Flash-Lite can serve as the "execution layer" in a cascading architecture where a Pro model plans and Flash-Lite executes.
UI generation: filling e-commerce wireframes, creating dynamic dashboards, generating simulations.
Video and image processing: with a 1 million token context, it can analyze up to 45 minutes of video or 3,000 images per request.
Companies like Latitude, Cartwheel, and Whering are already using Flash-Lite in production. Latitude reported 20% higher success rates with 60% faster inference. HubX achieved sub-10-second completions with 97% compliance.
How to Use the Gemini 3.1 Flash-Lite API
Flash-Lite is accessible through two main channels:
Google AI Studio: a web interface for rapid prototyping and testing. Ideal for experimentation.
Vertex AI: the enterprise platform with deployment management, enhanced security, and Google Cloud integration.
The model identifier is gemini-3.1-flash-lite-preview. It accepts text, code, images, audio, video, and PDF as inputs. Output is text only.
Key Features
Thinking Levels: you can adjust the model's reasoning intensity. A low level for simple, fast tasks; a high level for queries requiring more depth.
Function calling: the model can invoke external functions, making it compatible with agentic architectures.
Structured outputs: JSON generation, tables, and structured formats with high compliance rates.
Code execution: ability to run code in a sandboxed environment.
Context caching: cache context to reduce costs on repetitive requests.
Grounding with Google Search: anchor responses in Google Search results for improved factuality.
Technical Specifications
Specification | Value |
|---|---|
Context window | 1,000,000 tokens |
Maximum output | 64,000 tokens |
Images per request | Up to 3,000 |
Maximum video | 45 min (with audio) |
Maximum audio | 8.4 hours |
Knowledge cutoff | January 2026 |
Status | Public preview |
Is Gemini Flash-Lite Good Enough for Production?
The short answer: yes, for the right tasks. Flash-Lite is not a universal model. It will not replace GPT-5.2 or Claude Opus 4.6 for complex reasoning, in-depth legal analysis, or premium creative writing.
However, for high-throughput workloads where consistency and speed matter more than intellectual depth, Flash-Lite is a solid pick. Feedback from early testers confirms the model "handles complex inputs with the precision of a higher-tier model, while following instructions and maintaining adherence."
The cascading architecture recommended by Google is particularly compelling: use Gemini 3.1 Pro as the "brain" for planning, and Flash-Lite as the "reflexes" for execution. This approach combines intelligence with cost efficiency.
Strengths
Exceptional value for high-volume tasks
Top-tier speed (363 tokens/s)
Massive 1 million token context window
Excellent multimodal and multilingual performance
Adjustable thinking levels
Limitations to Know
No image or audio generation
Shallower reasoning than Pro or Opus models
Code performance below GPT-5 mini
Still in preview (no production SLA)
No support for Gemini Live API
Gemini 3.1 Flash-Lite vs GPT-4o-mini: Which Should You Choose?
The comparison with GPT-4o-mini is inevitable, as both models target the same segment. GPT-4o-mini is slightly cheaper on input tokens ($0.15 vs $0.25), but Flash-Lite offers a context window 8 times larger, superior benchmarks on most metrics, and significantly faster output speed. GPT-4o-mini dates from July 2026, while Flash-Lite benefits from training data up to January 2026.
For applications requiring long document processing, video analysis, or optimal multilingual performance, Flash-Lite is the clear choice. For quick prototyping at rock-bottom cost with short contexts, GPT-4o-mini remains competitive.
Google AI Model Pricing: Where Flash-Lite Fits in the Gemini Lineup
Understanding where Flash-Lite sits within Google's own ecosystem is essential for choosing the right model. The Gemini 3 series now spans three tiers:
Gemini 3.1 Pro ($2.00/M input, $12.00/M output): the full reasoning model for complex, multi-step tasks. Best for coding, research, and deep analysis.
Gemini 3 Flash ($0.50/M input, $3.00/M output): the mid-tier option balancing capability and cost. Good for general-purpose applications.
Gemini 3.1 Flash-Lite ($0.25/M input, $1.50/M output): the speed and cost champion. Optimized for high-volume, latency-sensitive workloads.
The pricing gap between Flash-Lite and Pro is substantial. Running one billion input tokens through Pro costs $2,000; the same volume through Flash-Lite costs just $250. For enterprises processing massive datasets, this 8x cost reduction can save tens of thousands of dollars per month.
Google also offers a generous free tier for Flash-Lite through AI Studio, with rate limits that early adopters on Reddit have described as "super generous" - enough for meaningful testing and small-scale production use.
Our Verdict
Gemini 3.1 Flash-Lite represents a significant milestone in the democratization of AI APIs. At $0.25 per million input tokens, Google delivers a model that surpasses the previous generation in both speed and quality while maintaining an accessible price point.
The model's real strength lies in its positioning. It is not trying to be the smartest model on the market. Instead, it aims to be the most efficient worker - handling the millions of routine tasks that power modern SaaS platforms. With an Elo score of 1432 on Arena.ai, benchmark-leading multimodal performance, and a 1 million token context window, it delivers far more intelligence than its price suggests.
For SaaS platforms like Emelia that process millions of data points daily, for agencies like Bridgers that build AI solutions for their clients, and for any developer looking to scale applications without breaking the bank - Flash-Lite seriously deserves evaluation. It is not the smartest model on the market, but it might be the most cost-effective.

Clear, transparent prices without hidden fees
No commitment, prices to help you increase your prospecting.
Credits(optional)
You don't need credits if you just want to send emails or do actions on LinkedIn
May use it for :
Find Emails
AI Action
Phone Finder
Verify Emails
€19per month
1,000
5,000
10,000
50,000
100,000
1,000 Emails found
1,000 AI Actions
20 Number
4,000 Verify
€19per month
Discover other articles that might interest you !
See all articlesBlog
Published on May 17, 2025
Mastering Competitive Analysis: Best Practices & Practical Steps
 Mathieu Co-founder
Mathieu Co-founderRead more
Tips and training
Published on Dec 5, 2022
Few things to avoid in your campaigns
 Niels Co-founder
Niels Co-founderRead more
LinkedIn
Published on Sep 2, 2025
LinkedIn and Beyond: Discover 6 Alternatives to Dripify
Mathieu Co-founderRead more
Software
Published on Nov 5, 2025
4 Translation Management Systems That Actually Make Global Expansion Easy (Not Overwhelming)
Niels Co-founderRead more
Software
Published on May 24, 2024
5 SalesQL Alternatives : 2026 B2B Prospecting Hacks
 Marie Head Of Sales
Marie Head Of SalesRead more
Software
Published on Nov 25, 2025
6 Corporate Tax Software Tools That'll Actually Save Your Sanity (And Money) in 2026
Niels Co-founderRead more
Made with ❤ for Growth Marketers by Growth Marketers
Copyright © 2026 Emelia All Rights Reserved